Cracking the Code: How LLMs Helped Me Master Spark’s Shuffle Tracking Feature
Navigating the intricacies of Apache Spark’s shuffle operations can feel like finding a needle in a haystack — unless you have the right tools.

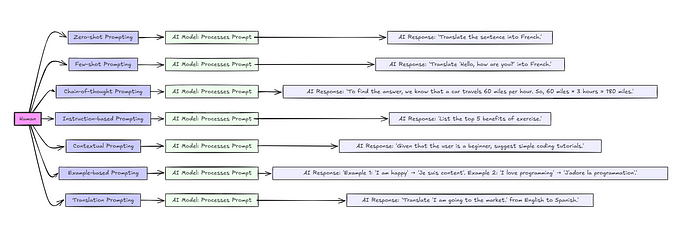
Recently, I dove into the Apache Spark codebase to understand its shuffle tracking feature — a critical component for optimizing data processing tasks. Traditionally, this would mean scouring through countless websites and fragmented documentation. But instead, I leveraged Large Language Models (LLMs) to streamline the process.
🔍 My Strategy: Using Specific Prompts to Unlock Insights
I crafted targeted prompts to extract detailed information directly from the codebase, below are some samples:
- “Explain how the shuffle tracking mechanism is implemented in Apache Spark, by parsing the code in https://github.com/apache/spark repository”
- “Describe how Spark tracks the completion of shuffle tasks and manages metadata.”
- “What optimizations does Spark’s shuffle tracking feature provide to improve performance?”
- “Detail the role of the MapOutputTracker and how it interacts with shuffle operations.”
- “How does Spark handle fault tolerance and data recovery in the shuffle process?”
The Outcome?
Without hopping between ten different websites, I gained a comprehensive understanding of:
- The implementation details of shuffle tracking in Spark.
- How metadata and task completion are managed efficiently.
- Performance optimizations that make shuffle operations faster.
- The critical role of MapOutputTracker in coordinating shuffle data.
- Fault tolerance mechanisms that ensure reliability during shuffles.
Why This Approach Matters
The world runs on open-source software, powering countless systems and innovations. Yet, many open-source projects suffer from a lack of adequate documentation, making it difficult to understand how the code works — ironically defeating the purpose of open collaboration. By leveraging LLMs with well-crafted prompts, we can:
- Accelerate our learning curve.
- Dive deeper into complex features without getting lost.
- Enhance our contributions to the open-source community.
My Takeaways
- Efficiency: I saved time and avoided the frustration of piecing together information from scattered sources.
- Depth of Knowledge: I obtained a level of understanding that would be difficult to achieve through traditional research alone.
- Empowerment: I’m now better equipped to optimize Spark applications and troubleshoot issues effectively.
Have you utilized LLMs to explore specific features in open-source projects? I’d love to hear your insights or any tips you may have in the comments. If you found this write-up helpful, feel free to clap 👏 or leave a comment or show your support.
I’m Hari, and I write about technology and programming. To receive my latest stories directly, consider subscribing to my newsletter.